

Authors:
(1) Yuxuan Yan,Tencent with Equal contributions and [email protected];
(2) Chi Zhang, Tencent with Equal contributions and Corresponding Author, [email protected];
(3) Rui Wang, Tencent and [email protected];
(4) Yichao Zhou, Tencent and [email protected];
(5) Gege Zhang, Tencent and [email protected];
(6) Pei Cheng, Tencent and [email protected];
(7) Bin Fu, Tencent and [email protected];
(8) Gang Yu, Tencentm and [email protected].
Table of Links
3. Method and 3.1. Hybrid Guidance Strategy
3.2. Handling Multiple Identities
4. Experiments
4.2. Results
We provide quantitative and qualitative results for comparison and analysis in this section.
Quantitative comparison with baselines. To evaluate our model’s ability to preserve identity during image generation, we conduct a quantitative comparison with baselines. We measure the Arcface feature cosine similarity [12] between the face regions of input reference human images and the generated images, with values in the range of (-1, 1). We consider both 1-shot and multi-shot cases, where only one reference image and 11 reference images are provided, respectively. The baselines we compare against include DreamBooth [43] and Textual Inversion [14], which are the most popular tuning-based methods, which are optimized with 1K and 3K iterations, respectively. We also incorporate our model variant that removes the identity input for comparison to measure the influence of identity information. For the multi-shot experiment, we compute the face similarity score between the generated image and each reference image and report the mean score for comparison.


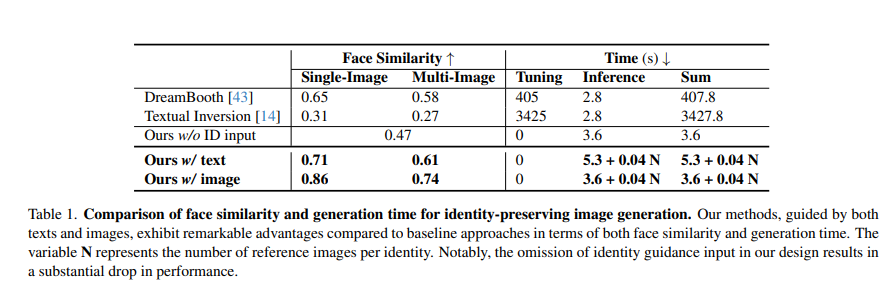
We have conducted experiments on 11 different identities, and we report the average performance for comparison, and the results are shown in Table 1. Our model demonstrates superior performance in both 1-shot and multi-shot cases, highlighting the effectiveness of our design in preserving identities. Notably, our advantages stem from the inclusion of our identity-guidance branch, as demonstrated by the performance drop in the baselines that lack this guidance.
Influence of the identity input. To further investigate the influence of the identity input, we conducted an ablation study through qualitative comparisons. We compare our model with a baseline model that removes the identityguidance branch, acting as an image reconstruction model. The results are displayed in Fig. 4. The image reconstruction baseline roughly preserves image content but struggles with fine-grained identity information. In contrast, our model successfully extracts identity information from the identity-guidance branch, resulting in improved results for the face region.
Novel view synthesis. We conduct novel view synthesis experiments to validate our algorithm’s effectiveness in synthesizing images with large pose changes while preserving identity. Results are presented in Fig. 5. The result demonstrates that our algorithm can synthesize high-quality images with preserved identities even when faced with significant pose changes, which showcases the robustness of our design.
Dual guidance experiment. We explore the combined use of text-based and image-based guidance during inference by controlling the strength of both types of guidance using the hyperparameter, α, within the range [0,1]. The results, presented in Fig. 6, illustrate that our model can effectively utilize both types of guidance for image synthesis while preserving identity information. By adjusting α, we could see how the influence of each type of guidance changed.
Identity mixing experiment. Our model’s ability to mix identity information from different humans during image synthesis is showcased in Fig. 7. By controlling the mix ratio within the range [0,1], we assign weights to different identities. As is shown, our model effectively combines identity information from different people and synthesizes new identities with high fidelity.
Multi-human image generation. One of our model’s unique features is synthesizing multi-human images from multiple identities. We present the results in Fig. 8, by comparing our design to a baseline using vanilla cross-attention mechanisms. As the result shows, our model effectively correlates different human regions with different identities with our proposed enhanced cross-attention mechanisms to differentiate between identities, while the baseline results in confused identities in the human regions.
More qualitative results. Fig.10 showcases a new image synthesis method, which is an extension of the image-to-image generation technique originally found in StableDiffusion[42]. This method has only minor variations from the primary pipeline discussed in the main paper. In this approach, the diffusion process begins with the noisy version of the raw human images’ latent representations, with the rest of the process unchanged. This specific modification ensures that the synthesized images retain a layout similar to the original images. Our results demonstrate that, despite these adjustments, the method successfully maintains the identity of subjects in the synthesized images. Additionally, Fig. 11 provides more qualitative results of our model when applied to a broader range of image styles. These results highlight the model’s adaptability to various artistic styles while still holding true to the core objective of identity preservation. This versatility is crucial for applications that require a balance between stylistic expression and the need to maintain recognizable features of the subject.
This paper is available on arxiv under CC0 1.0 DEED license.